Probable People
I think it's safe to say that, of the many hobgoblins of the typical programmer, the free-form text field is among the worst. I would hate to guess at how much time I've spent and how much code I've written just to deal with overly-permissive catch-all fields (many of which I put into place myself).
But having been bitten over and over by this issue, I've finally developed a fairly decent tool-set to deal with the parsing and cleaning up of such data. I though I'd give a shout out here to a couple of my favorite tools which, like many great libraries, are minimal and specific. They've saved me untold hours, are impressively powerful and even fun to use.
The first library is libphonenumber by Google. At first glance you'd think parsing phone numbers would be fairly straightforward. Sure, you might think, you've got your (555) 555-5555 vs. your 555-555-5555 but you can just strip out the non-numbers and then format it however you like. But, if you have a large dataset the exceptions quickly start piling up with things like international formatting and extensions: 1 (555) 555-5555, +15555555555, 1-555-555-5555 x55, 001 555. If you need to also validate whether it's a valid number then you're lost. This library handles that case, and I've used it off and on since the early days of my career, when I was coding in Java and this library was still stored on its own code repo called Google Code. Here's an example of using the Python port of this library to parse a whole range of messy formatting, converting them to local and international formatting:
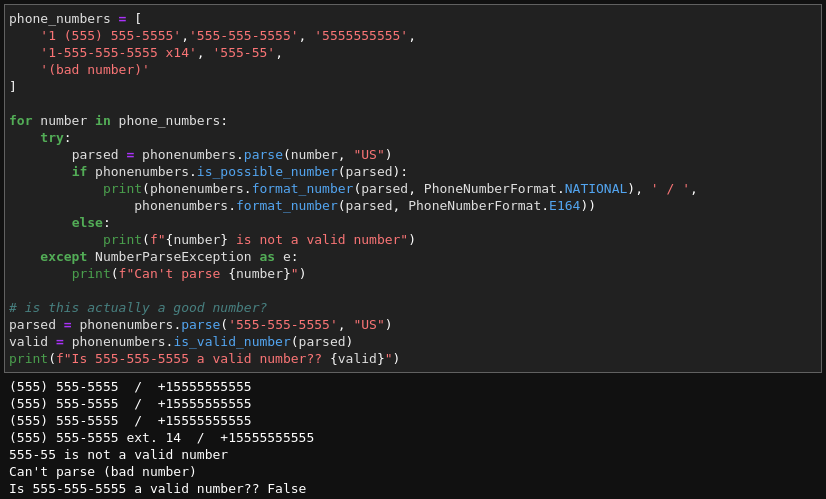
Doing this by hand would be a nightmare.
The other scenario I've run into recently is having to break out a full name field into first and last names. As with phone numbers this seems deceptively simple at first. Just split on the space character, right? But again we quickly run into myriad edge-cases: "Dr. Sandy Smith", "Sandy and John Smith", "John Smith Jr." and so on. For this issue, I reach for the wonderfully-named probablepeople library, which I learned about from Katharine Jarmul, who was recently a guest on TalkPython. probablepeople uses natural language processing for parsing data like this and guessing at the various name components. Here are a few examples of this library in action:
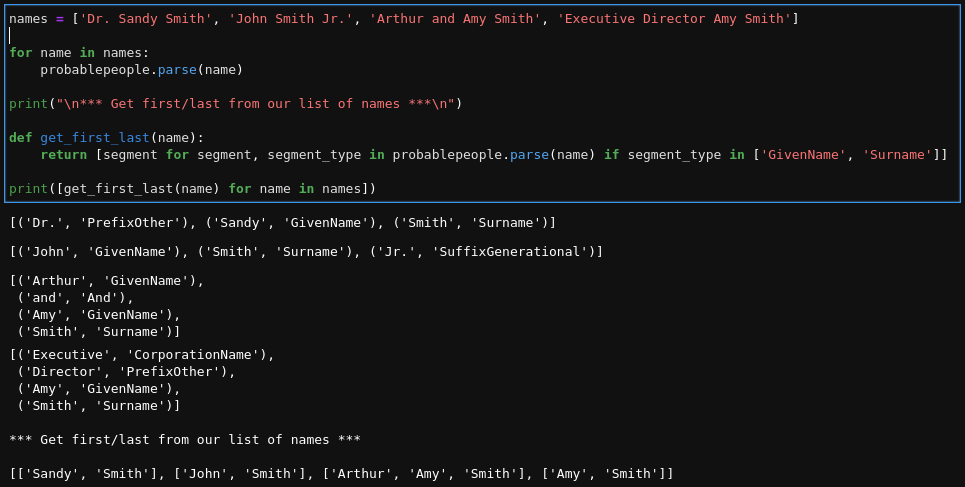
Notice how it gives you common name segments like surname and given name, but also catches things like corporation names, "PrefixOther" for "Director", and even instances where you have two names. This is brilliant, it allowed me to quickly process thousands of records. It didn't catch every name, but the rows that it missed were so few that it was easy to look through those by hand.
It's scary to think of how much time it would have taken me to try to do these tasks on my own. The fact that these libraries exist and that the maintainers bothered to write, document, test and, critically make them available to anyone is huge. It's the reason organizations like the one I work for – smaller non-profits – can do what we do with the resources that we have, at least from an IT perspective. It's amazing to think of how much productivity open source enables globally, how much cost it saves.
I was working in IT in the good old days when proprietary software was the rule more than the exception. I remember per-seat licenses being the norm and convoluted setups that were strictly there to limit access to products. Maybe it's for that reason that open source libraries like the ones I mentioned here still strike me as amazing and revolutionary. So a huge thanks to the maintainers and contributors of these projects for making the lives of people like me so much easier.