Dask
It's been awhile since I've written about anything technical, mostly because I've been busy and not really investigating anything new. But recently, and largely on whim, I've checked out a course on Dask. This is a framework for doing parallel, scalable data operations using Python.
Many of the reasons I listed in this post for not picking up Pandas for a long time apply here. I don't work on datasets large enough to warrant using multiple machines, I don't really do "data science", and I don't tend to have datasets so large they don't fit in memory and such. But after hearing about Dask enough I was convinced to check it out. Even if you're not using multiple machines this framework helps you to easily scale you programs to use all of the resources on your own local computer, which can really help for certain operations.
From the get-go I've been really impressed with Dask. Parallelism is hard in any language. It's difficult to get right, difficult to understand even when you do get it right, and it can go wrong in ways that are more troublesome than with sequential single-threaded operations. I've done just enough parallel computing to really appreciate when it's done well, and Dask seems to do an excellent job of making all of that hard stuff transparent for you.
In the course they have you start off by downloading a massive dataset of taxi data for New York City. It's nearly 8 GB of data divided up by month and year. It's more than my laptop will load into memory and would be a big hassle to do anything meaningful with. Even just loading one month basically stalls out Excel. The question posed to you in the training is to find the average tip amount based on the number of passengers and, after that, to find the standard deviation of tip amount also by number of passengers.
You could do this manually of course. You could load the files in chunks, calculate intermediate values, and add it all together in the end, but it would be such tedious and error-prone work. With Dask this is a couple of lines, and you can even use intermediate results for multiple calculations (for example, once you group by passenger_count you can use it for both the mean and standard deviation):
# prepare all 2019 sheets (creates partitions and figures out data types of columns)
df = dd.read_csv("data/yellow_tripdata_2019-*.csv")
# get the mean tip amount by passenger count
mean_tip_amount = df.groupby("passenger_count").tip_amount.mean().compute()
# get the standard deviation
std_tip = df_dask.groupby("passenger_count").tip_amount.std().compute()
That's a couple of lines of Python to do a horrendously complicated series of tasks, and there are numerous ways to make it even more effective, like sharing intermediate results between the two calculations.
Before running these operations you create a client, which is where you define how many "worker nodes" to use and where computations are done. This is where you would configure things like whether computations should be done on cloud computers, how many CPU cores to use and that sort of thing. By default it will use your local machine and all of its cores:
from dask.distributed import Client
client = Client(n_workers=4)
client
Here's what the client shows you:
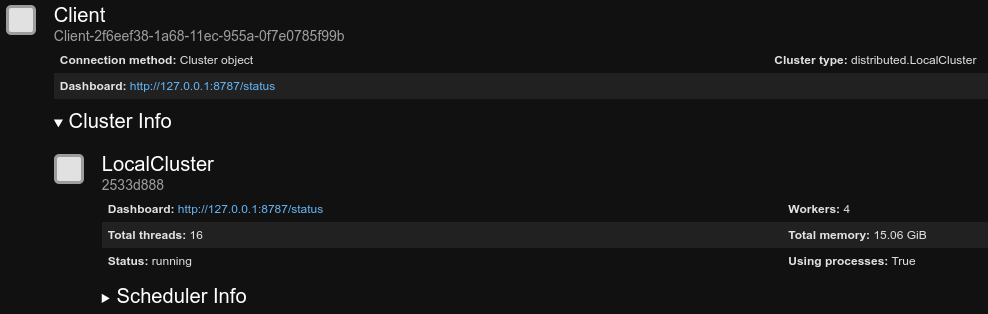
Following the Dashboard link reveals one of my favorite features of Dask. You can actually watch your operations being done in real time. On the dashboard you can see things like CPU cores being used, worker nodes communicating with each other and what phase your operation is in. It's absolutely amazing to watch all of the cores of my laptop light up and see the workers talking to each other during a massively parallel operation.
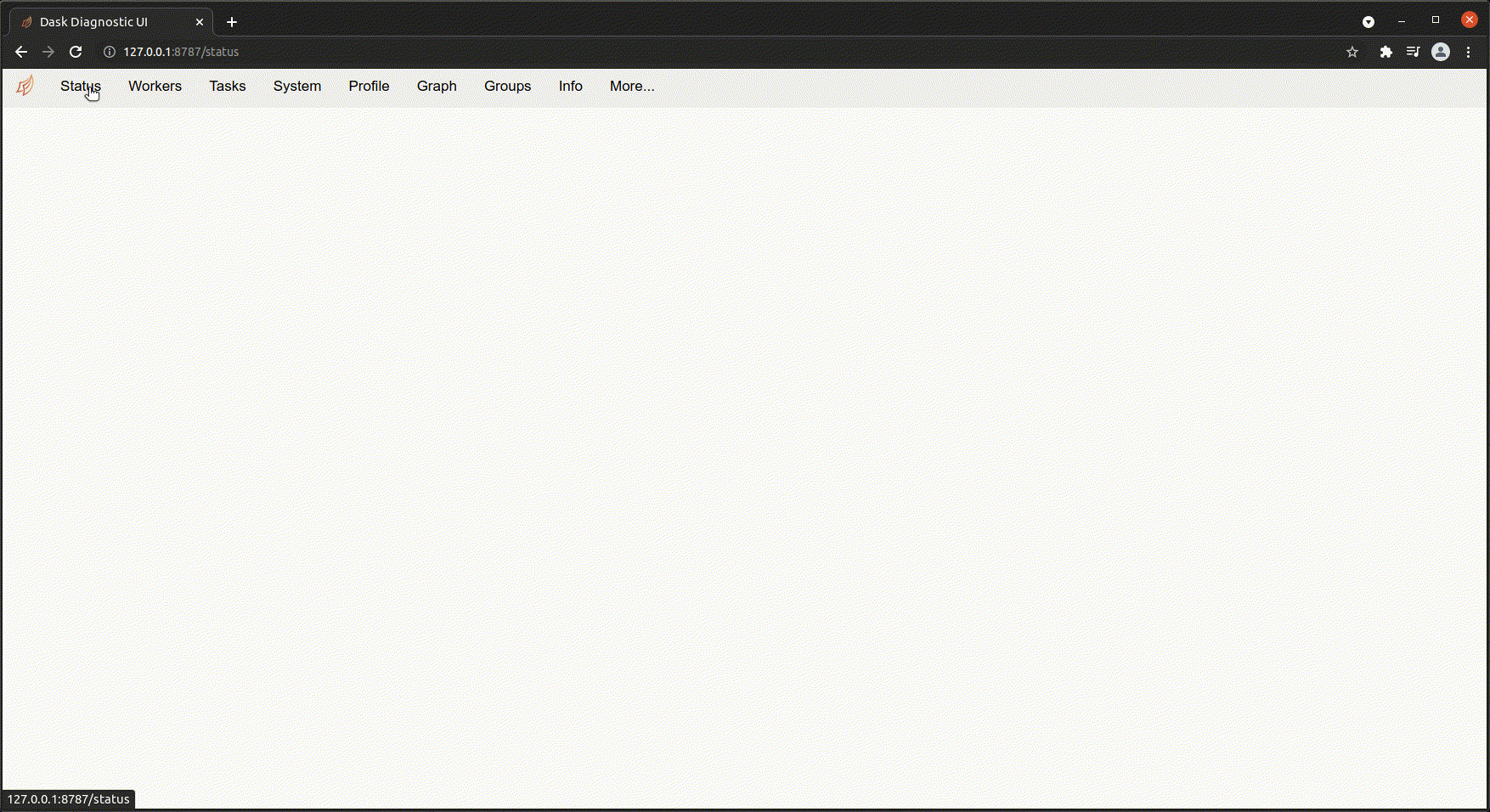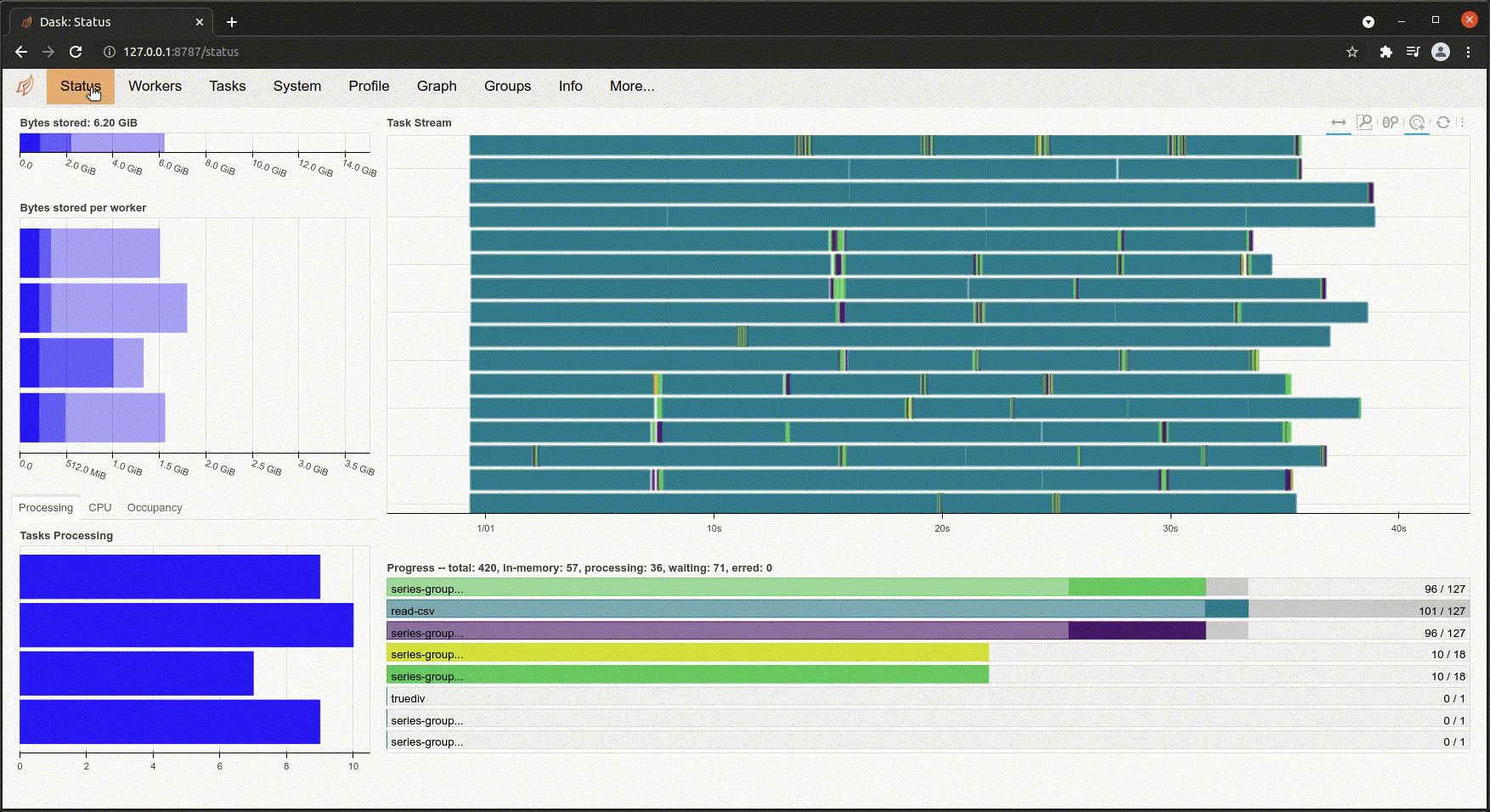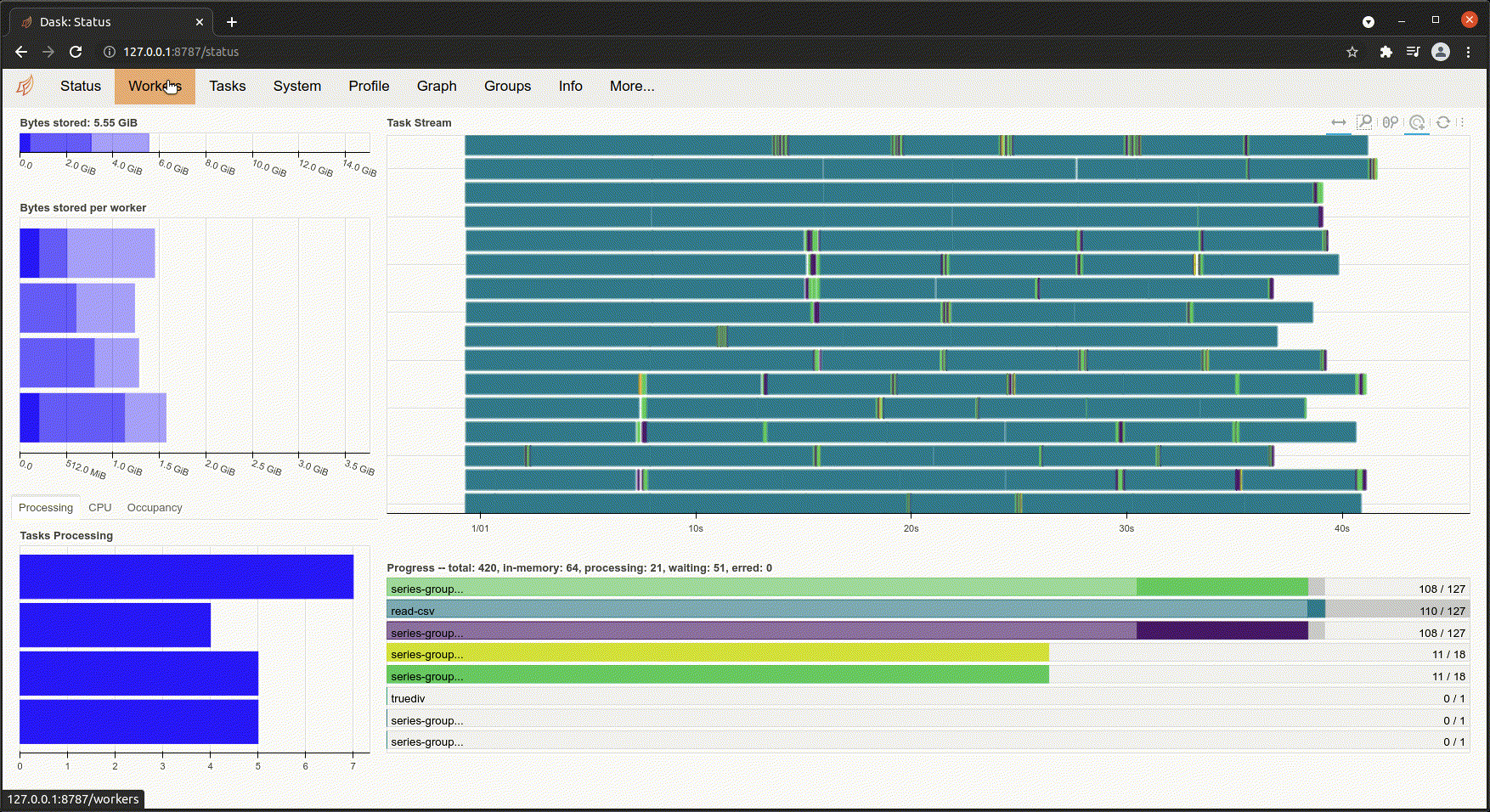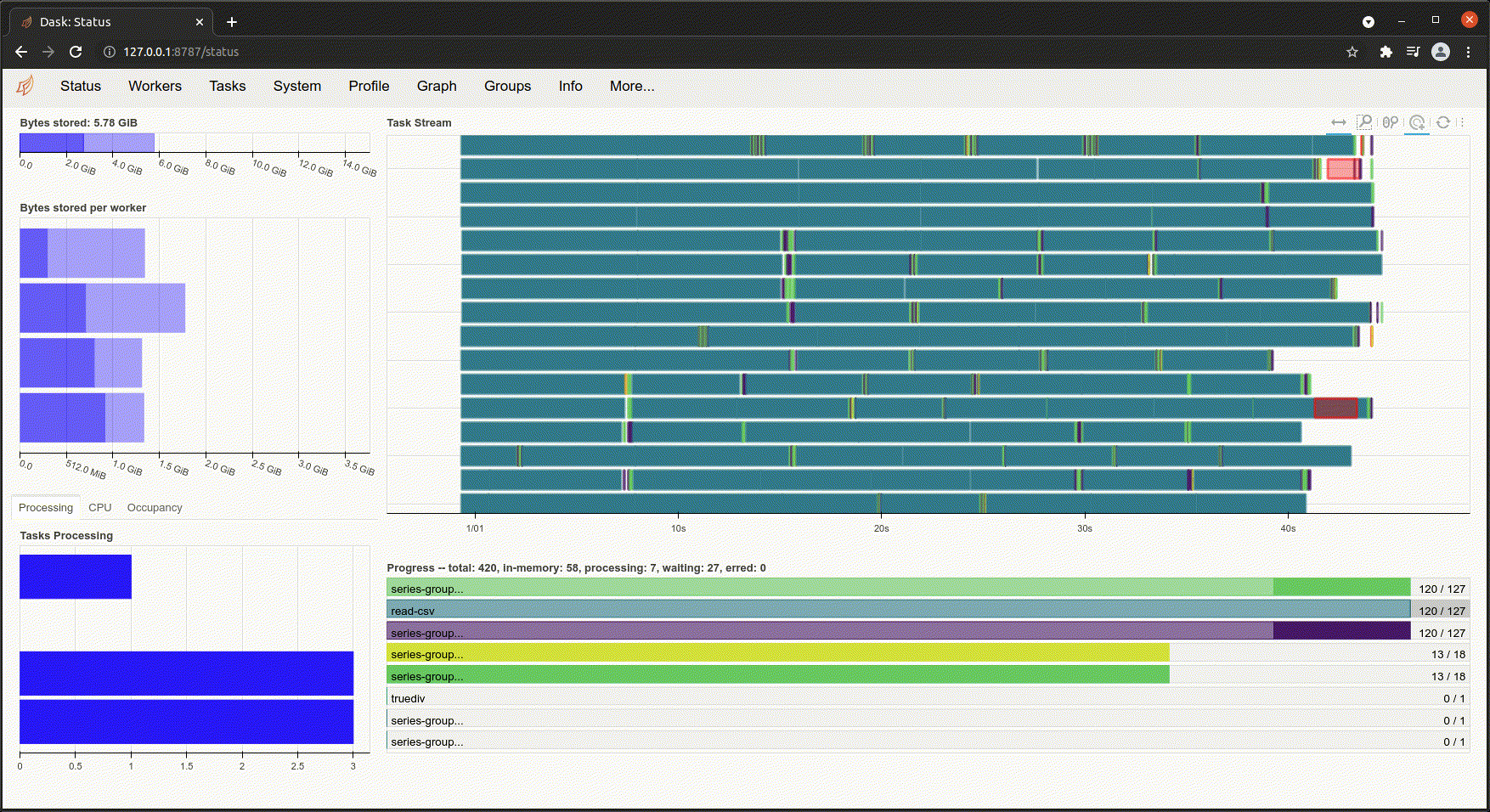
Besides being awesome to look at, this really drives home just how much complexity is involved in a seemingly simple operation when you're dealing with parallelism and large datasets.
As I mentioned at the beginning of this post, I don't often have constraints that require this kind of parallel solution. But, as with Pandas, I can foresee this making my life easier even if I'm not using it to it's fullest extent. I do occasionally use threads and such for work that I do with API integrations, and Dask has tools like Delayed and Bag which allow you to run tasks separately from DataFrames. I also occasionally work with datasets that, although not too big for memory, are large enough to be slow to load and work with, and I'm betting this will speed that sort of task up by a lot.
I will report back as I go through this course and learn more, but so far I'm very impressed by this library. And it's especially awesome to see it being used by efforts that I'm really excited by like the Microsoft Planetary Computer and Pangeo.